機械の背景、夕景、キャラクタ
機械背景、キャラクタ前景
機械背景はループとブラー、キャラクタ前景は髪揺らし
ある点で機械背景途切れ、夕景背景に入れ替え
夕景背景は少しずつカメラ下ろし、キャラクタ前景は髪揺らしはそのまま夕景に合わせ影動かし
機械背景
ループ画像と、ループ途切れ部分持ち画像(上下)
OutPaintで伸ばすだけ
夕景背景
カメラ下ろし
デプスと合わせてVertical視差を作る
GitHub - akatz-ai/ComfyUI-Depthflow-Nodes: An implementation of Depthflow in ComfyUI
太陽の光
出てきた瞬間IC-Light
ただこれリアル調っぽい……もう少し情報を集めよう
GitHub - kijai/ComfyUI-IC-Light: Using IC-LIght models in ComfyUI
やっぱりというか、環境光しか出せない。
仮にIC無しで光を作る場合
hunyuanで動画
始点、中間、終了Fをdepanyv2でdepth取って、2値化で切り合成
再度動画化
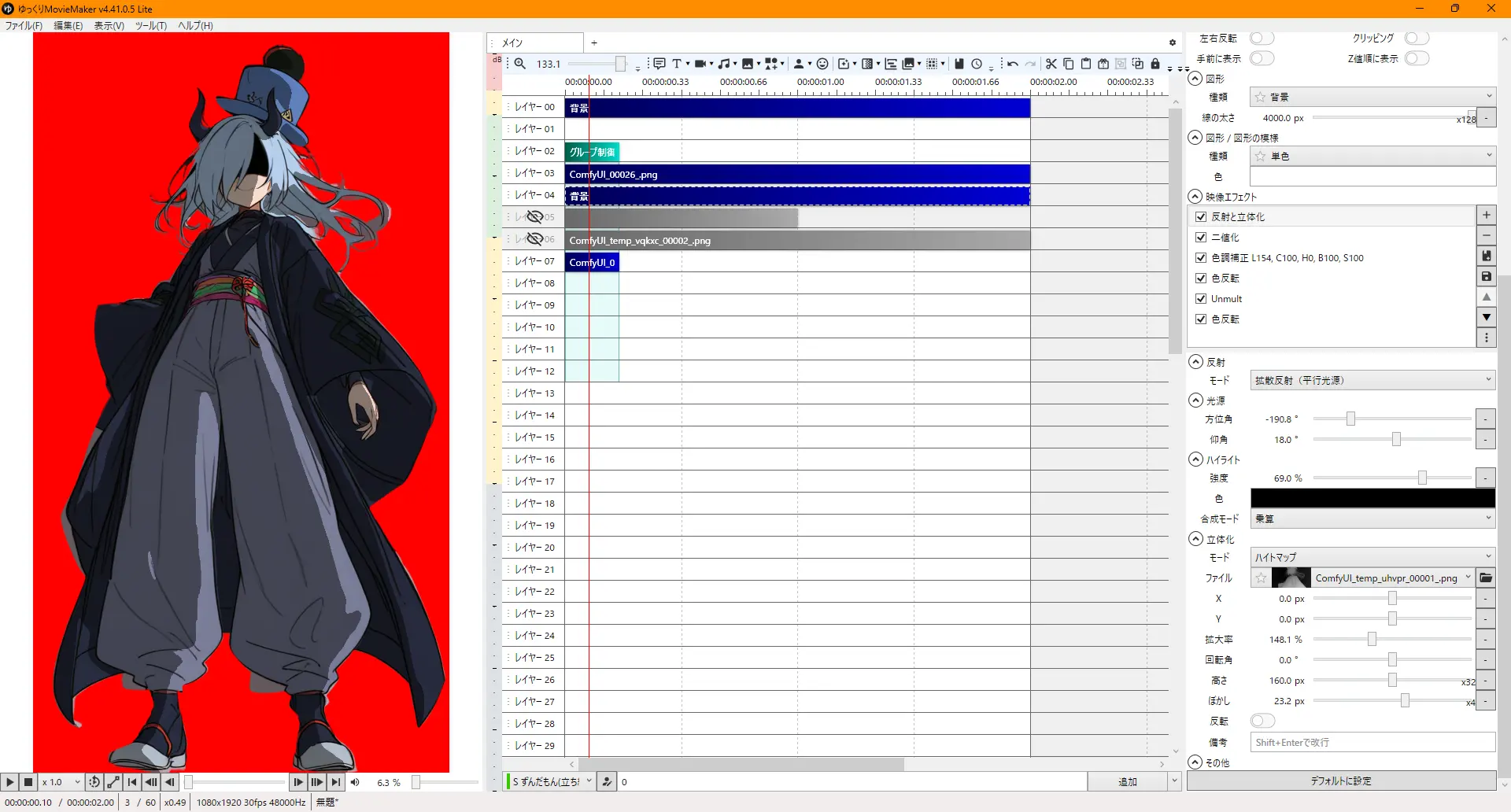
反射立体にdepth使って影づくり。
白の背景に反射ハイトマップdepthぼかし、二値化でアニメ影化、色調補正で薄め、色反転してからUnmultで黒を透過して再度色反転で影を戻す。
Unmultが無いならキーイングや加算合成になるが、白飛びとかするらしいので
あと周りに影が結構はみ出るので結局birefnetマスクで削除グループ合成が必要。
そこそこいい絵だが、顔への落ち影が酷い
顔だけsegmentして別に取る工夫が必要
結局craig-martinが一番うまく下塗りできる。
hsv
cscfill
flat_color
どの手も微妙だった。
やっぱりcraigがナンバーワン。
ただし色指定が出来ない。animagin単体は髪の色だけは外さないが、ウェイト落とさないと髪すら色がずれる。
あとこの色で作品を成立させるためかやたらギラギラする。
色ならLayerDividerで何とかなるかと思ったが、分けた後にその色がどこの物だったのか説明できない。
i2iでけっこう上手くいった。
craigは色分け雑なので、切抜きとかと合わせて背景を消しつつ……i2i程度で行けるならILで(flat color:1.5)もありか。
あとはこれに顔落ち影対策、framepackで落下を作る。
なのでまずは落下中の一枚絵を生成する。
最初の絵を背景切抜きIP-Adapter、プロンプトでfalling, sky, squatting?, sitting?, from_side?を追加。落下姿勢を取らせる。
librasよさげ。
ntr,sudachiは動かすのに向いて無さそう。
nnailousはいまいち制御できない。
obsessionは絵柄はいいがしゃがみ具合が。V-predictionでも微妙。
novaflatあり。animeクソ。
キャラクタ前景
落ちながら髪を揺らすだけ
framepackで可能不可能を見る
fpは30GBくらい使うらしい
sdxlの使用容量を考えるとギリギリなので、これは単体で動かしたほうが良さげ
Framepackのモデルはbf16でエンコされてる。bf16が使えるRTX30XX系じゃないと使えない。Oh…
compute capabilityというのが8以降じゃないとbf16が使えないらしい。
t4は7.5でp100は6。
NVIDIA CUDA GPU Compute Capability
kijaiのwrapperなら動くかもという報告。
f1用のもあるしいけるか?
t4 shader model 6.8
NVIDIA Tesla T4 Specs
p100 sm6.0
NVIDIA Tesla P100 PCIe 16 GB Specs
sage-attentionを使用するにはSM8が要る。
triton + sageattention error: RuntimeError: PassManager::run failed · Issue #6228 · comfyanonymous/ComfyUI
flash-attnはコンパイルが終わらない。CPUだとインストールは6GBでできるっぽい。だがGPUだとダメになる。torchバージョン?
xformersはカツカツな容量からはみ出る。
!pip cache purge
!conda clean -a -y
これでキャッシュを消してもxformersは足りない。cudnnまでいれるためか10GBが軽く飛ぶ。
しゃあないのでsdpa。
fp8じゃないとkaggleの50GBに入らない。
bf16を元にfp8_e4m3fnにしたよという設定にしないと黒の画像が出力される。
load_deviceはoffloadでCPUに出す。それでもCPU27.6GPU13。
VAEもbfじゃなくfpを使用。
縦640だと30step5秒で5700秒。1.58時間。
teacacheを使うと2回目以降が無理。
HYは適切な解像度がある。大きすぎると遅くOOM、小さすぎても。
Update framepack_hv_example.json by Crimsonfart · Pull Request #1 · kijai/ComfyUI-FramePackWrapper

動くには動く。
既に画面にある要素を説明する必要はない。副詞を付けるといいらしい。カメラは基本固定。ズームやパンを繰り返せと言われたら一応繰り返すとか。
r/StableDiffusion - Reddit
r/StableDiffusion - Reddit
skyreels v2というvram10gbで動く動画生成がある。
GitHub - kijai/ComfyUI-WanVideoWrapper
Framepack-tudioでは秒ごとに異なるプロンプトを指定できる。
r/StableDiffusion - Reddit
wan
r/StableDiffusion - Reddit
wind flowing up,
the girl is falling, A strong wind is blowing up the girl’s hair and clothes.
The girl falls. A strong wind blows up her hair and clothes away.
本来HYは9:16なら縦960スタート。
GitHub - Tencent/HunyuanVideo: HunyuanVideo: A Systematic Framework For Large Video Generation Model
落ちる一枚絵から、キャラだけ切り出し背景をinpaint。
キャラが落ちているかのような二枚を作ってframepack。
これでも下に落ちていく動画しか取れないので、やっぱfizznodesか。
髪と服に関する部分を0.01くらい弄って動かす。
これ一貫性持って変更できないことに今更気づく。
やはりfpでなんとかするしかないのか。studioなら秒ごとに違うプロンプトを指定できるらしいので、これで同じように0.01ずつ変えれば?
0.01とかそういう数値じゃない。元のHYがLLMでプロンプトを処理しているので自然言語しか使えない。
そうでなくとも大きく動いてしまうFPで、プロンプトを変えた程度で髪だけ動かせるとは思えない。
髪だけマスキングを考えたが、拡大でマスクが顔にかかると変化してしまう。
髪と背景一部だけマスキングして顔をマスキングしないようにすればいいがそんなものはない。
というかマスキングできたとして、画像生成をかければ色が変わってしまう。それでは意味がない。
wanのloraではいくつか一部だけ動かしている絵がある。
pixelのやつは元に頼っている。
動画生成のテキストエンコーダ―t5の改良版umt5。
danbooruタグがある程度効くのが確認されている。
Image posted by motimalu
live2d animation、floating hair
flat color loraの適用で髪の動きが増えてるので、元の癖か。
sigclip(clip vision), umt5(clip), gguf vae, gguf model。
wanはclip_vision_hらしいので買えるのは不味そう。
wanはshift値が必要。標準のModelSamplingSD3ノード。
高解像度でノイズを管理するらしい値。
Stable Diffusion 3 で最高の結果を得る方法|AICU Japan
i2vに1.3bモデルは存在しない。
というかt2vにしかない。
WAN 2.1 480 GGUF Q5 model on low VRAM 8GB and 16 GB ram fastest workflow 10 minutes max now 8 mins | Civitai
🦊Wan2.1 - work4ai
流石wan、かなりいい
flf2vは使うとむしろ不自然。
これは最後の瞳ズームにしか使わないか。
キャラ一貫性
r/comfyui - Reddit
instantcharacter
24gb
dreamo
GitHub - bytedance/DreamO: DreamO: A Unified Framework for Image Customization
2025.04.24
flux
infiniteyou
acepp
ali-vilab/ACE_Plus · Hugging Face
editor
flux.1-fill-dev
開発中止してVACEに移行している
personalize anything
Personalize Anything for Free with Diffusion Transformer
inpaint,flux
顔pulid
GitHub - cubiq/PuLID_ComfyUI: PuLID native implementation for ComfyUI
skyreelsだと一貫性を保ち切れずよくわからない塊になってしまう。
結局wanのi2vで何とかするしかない。
live2d animationでfpもいけるかと思ったが、動きすぐで服の模様が消えるのと解像度限界が近い。
vaceのreferenceを使う方法は、どうやらキャラだけ抜き出して作り直す機能らしい。
ただそのキャラ抜出の精度はあんま高くない。wani2vつかって。
anisoraは重すぎ。量子化待ち。
GitHub - bilibili/Index-anisora
llama.cppのconvert_hf_to_gguf.pyと、ビルドで出るllama-quantizeで量子化可能。
Error when using convert_hf_to_gguf.py for Q5_K_L · ggml-org/llama.cpp · Discussion #11088
GGUF
Tutorial: How to convert HuggingFace model to GGUF format · ggml-org/llama.cpp · Discussion #2948
Tutorial: How to convert HuggingFace model to GGUF format · ggml-org/llama.cpp · Discussion #2948
llama.cppでLLMを量子化し、ollamaで動かせた!これで勝つる!(cyberagent/calm2-7b-chat量子化記事の再現編) - nikkie-ftnextの日記
GGUF 変換メモ - Qiita
色調補正をデプスマップを元に掛けたい。
AEなら調整レイヤーの仕事。YMMなら色調弄った後のやつをデプスで切り抜いて弄ってないのを表に出せばいい。
空気遠近をデプス程度でやるとミニチュアになる。
結局キャラクターをanisoraで用意した
あきた。
Cosense